
Serverless computing: even without servers!
How does serverless computing work? What are its advantages, disadvantages and how does it differ from PaaS services?
Martin Gavanda
How would you like to run applications without worrying about any server infrastructure, be able to react to performance spikes in seconds (or even less), and pay for it all based on actual usage of individual services? Serverless computing services make all this possible. No more servers!
Of course, you can’t do it without servers, but from the user’s point of view, the servers are hidden, you don’t pay anything for them, and most importantly, you don’t have to take care of them. Serverless computing is a relatively new approach for the operation of certain types of applications, which is based on the concept of platform as a service (PaaS) and takes it a step further in terms of dynamism and flexibility of operation of individual applications.
What is serverless computing
Simply put, serverless computing is about providing certain platform features in the form of a pay per use model. With standard infrastructure as a service (IaaS) or PaaS services, you typically pay for a certain “size” of the service, usually defined by performance (2 vCPU, 8 GB RAM). In the case of serverless computing, on the other hand, you pay for the “volume” of use of a given service:
- how often you run a business function,
- how many milliseconds of CPU time a single execution of your application consumes,
- how many messages your apps have exchanged,
- how many resources your application has used.
In the context of Cloud computing, we can meet the abbreviation FaaS, i.e. Function as a Service.

Nowadays it is possible to draw various kinds of services in the form of serverless computing:
- Services for running applications, code or even Kubernetes
- Database services, both standard relational databases and object
- Different integration services, notification services, queue processing services or APIs
- AI and machine learning, text recognition, video analysis or even interactive chat services
So we can think of serverless computing as a pool of resources that are available to me, and every time I use a resource, I pay for it.
Basic differences from PaaS services
Serverless computing and platform as a service are similar in many ways. In both cases, there is no need to worry about the “underlying infrastructure”. In both cases, you don’t even have to worry about the operating system and middleware. From my perspective, the most significant difference is the pay-per-use model and the dynamics of serverless services.
Example 1: Application
Standard PaaS
If you use standard PaaS services to run applications (such as Azure Web Apps or AWS Elastic Beanstalk), you always pay a flat rate for the underlying infrastructure size (typically some equivalent number of CPUs and memory).
You need to know your application, its performance characteristics, and then select the optimal size of the underlying instance based on that. At the same time, it is necessary to take into account the architecture of the application and adequately adapt other follow-up services and technologies (such as Load Balancing), horizontal scaling and so on.
Serverless computing
If you decide to use serverless computing, you typically use Azure Functions or AWS Lambda, where you pay to execute (run and perform) a specific function. Let’s think of a function as a clearly defined operation, for example “take an input image, perform an operation on it, report the result to another function and save the image”.
It doesn’t matter if you run a function four times a month or a thousand times a second. You need to know only one thing: what power is needed to perform this function(for example CPU power or available memory) and you don’t care about anything else. The platform automatically provides enough resources to execute the function and you only pay for the time the function runs (usually billed in milliseconds).
To be even more specific, for example, AWS Lambda is charged based on the “number of calls” to the function ($0.2 for every 1 million) and the allocated “time memory” (for example, $0.0000000333 for 1 ms with a 2 GB RAM allocation).
So what does this mean in terms of costs? If you call your feature 5 times per second consistently throughout the calendar month, you will pay $2.59. The function takes 50 ms to process. This results in an additional $1.94. That’s a total of about $4.5 per month. Whereas AWS Elastic Beanstalk (a t2.small instance) would cost you roughly $19 per month, AWS Lambda is roughly 4x cheaper in this particular example.
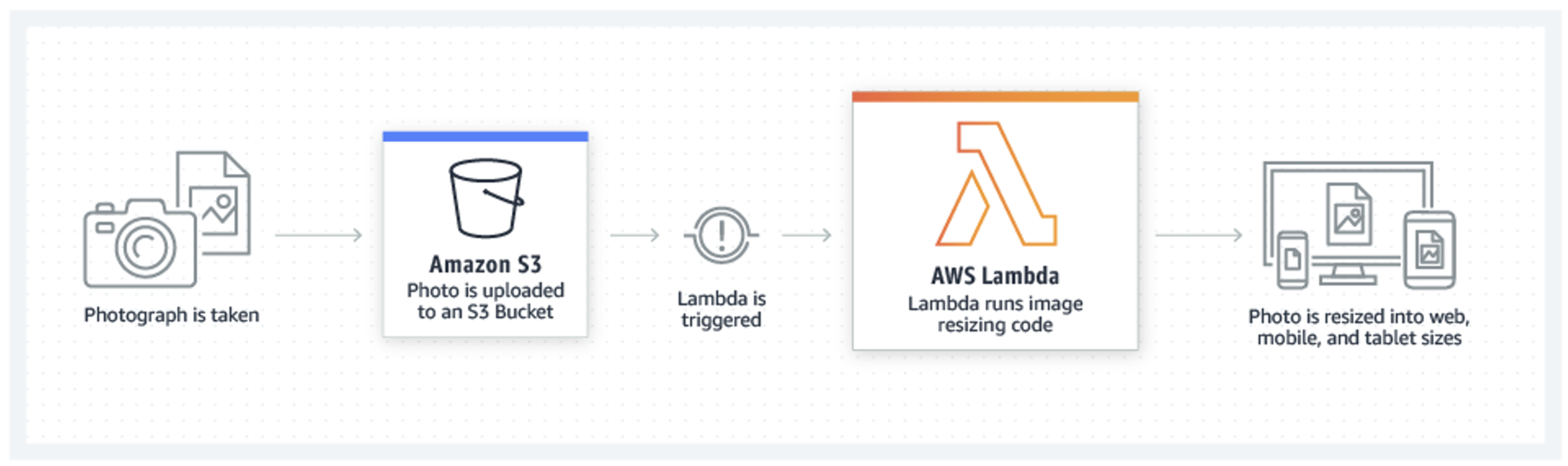
Example 2: Relational database
Standard PaaS
In this case, it is again necessary to define the “size” of the database instance itself and this performance is assigned to the customer. If your application doesn’t use it, it’s a wasted investment. Conversely, if a situation arises where the application needs more performance, it is not entirely easy to react to this situation and “scale” the database on the fly. Yes, there are options, but it’s not trivial and your app needs to be ready for it.
Serverless computing
If your application has variable performance requirements that change dramatically over time, it may be ideal to use a serverless database such as Azure SQL Database or AWS Aurora. Be sure to study the documentation of each clamp in detail, because the serverless option is not available for every type of database engine or specific configuration.
With a serverless database, you again pay for the allocation of specific performance over time. For example, in the case of Azure SQL Database in serverless mode, you pay €0.0001345 per vCore (processing unit) per second of usage.
Of course, you can define the minimum and maximum required performance values, and you can even specify whether the database service can be temporarily suspended when it is not in use. Your database will then dynamically allocate a sufficient number of vCores so that you are able to achieve optimal performance.
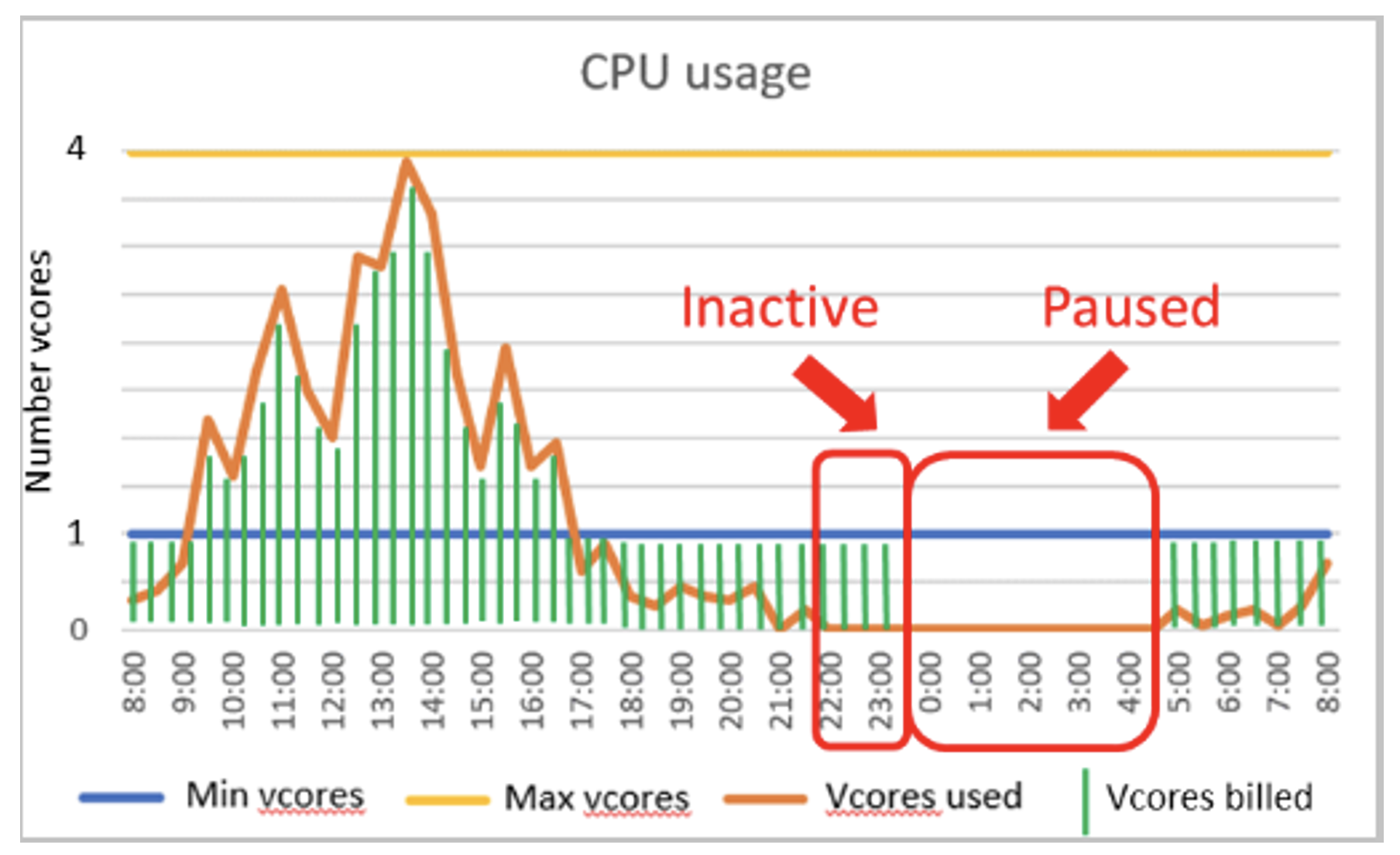
Let’s compare costs again. Two vCores provided in PaaS “provisioned mode” cost approximately EUR 356 per monthin Azure SQL. In FaaS mode, the same database costs $0.5218/vCore-hour. If we use it during working hours at an average of 1 vCore, we will probably receive an invoice for a little over 100 EUR while maintaining the same performance parameters.
It’s not all gold that glitters
As is often the case with technology, there will always be advantages and disadvantages, so you need to consider when a particular technology is right for you. This is also true for serverless computing.
From my point of view, I perceive three main disadvantages of serverless computing:
- I need to know my application and its performance requirements in detail, which may not always be easy to determine. If my application doesn’t have performance spikes and is under constant load, serverless computing is likely to be more expensive than standard PaaS or IaaS services.
- It is not possible to run all applications using serverless computing, for example it is not suitable for monolithic Java applications.
- I need to know all the nuances of each serverless service, because as they say, “the devil is in the details”. Hand in hand with flexibility always comes a certain platform boundedness. Whether these are different “minima-maxima” or limitations of a specific technical implementation.
What applications should I use serverless computing for?
Because serverless computing is a relatively new form of service delivery, it is primarily suitable for newly developed applications. There are certainly scenarios where a complex refactoring of an existing application (especially an application with highly variable performance requirements) can make economic sense.
In general, I would use serverless computing primarily for newly developed applications, where with the right implementation you can achieve de facto unlimited possibilities in terms of scaling and performance at a very reasonable price.
This approach is also associated with another concept of application architecture, the so-called event-driven approach. Previously, apps “just ran” and were “available to anyone at any time”. Event-driven architecture is based on the premise of “reacting to an event”.
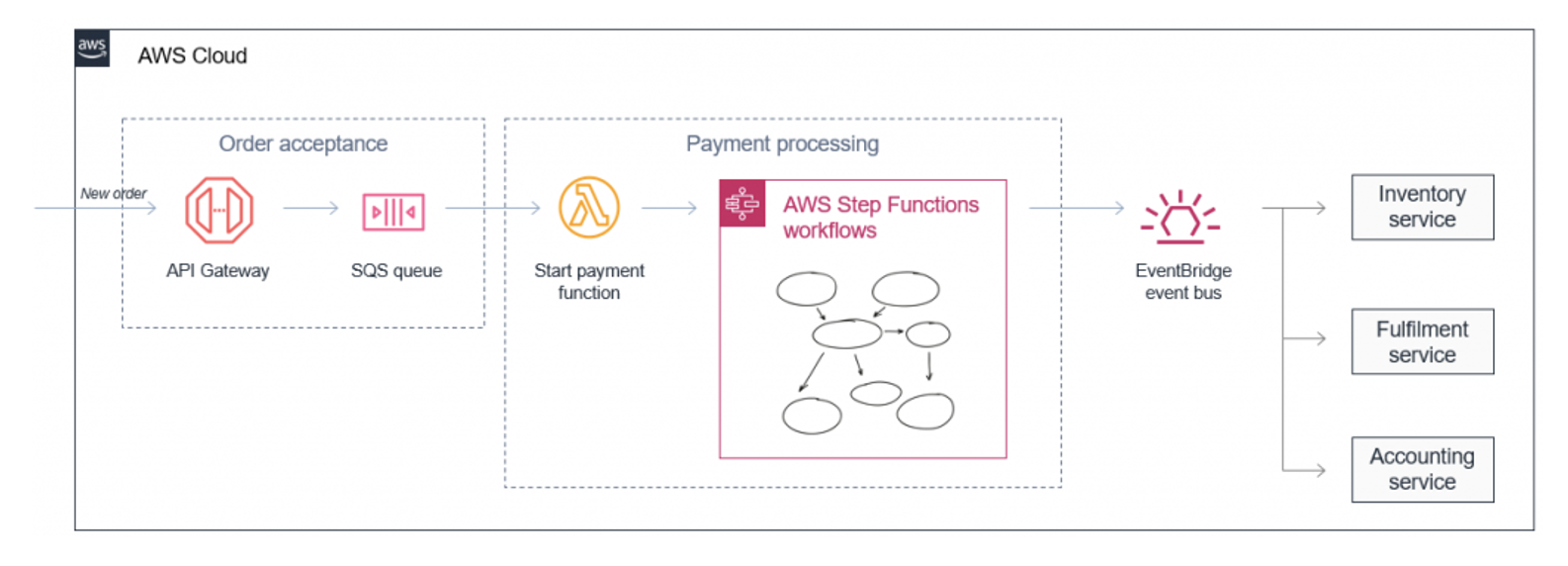
So we typically have producers of these events (something happened; a user uploaded an image, a business transaction was triggered, an account status changed, a new order arrived).
Then there are the event router components that are responsible for routing messages to individual subscribers (who should know about this; if there is a new image, this and that needs to be done, the new order needs to be processed by these downstream applications).
The last link in the chain is the processors (consumers)themselves. They are responsible for executing a certain action based on a specific event (what is to happen; if a new image has arrived, certain operations need to be performed, a new order means its processing and entry into the ERP system).
Serverless computing: Yes or no?
Serverless computing is not suitable for every software implementation, but the more my applications are “cloud native” and developed for the cloud environment, the more potential benefits serverless computing offers me.
With the right use of serverless computing, my application can be much more robust, cheaper and more accessible than traditional PaaS services.
So how do you decide which applications to use which service and technology for? This is what my colleague Lukáš Hudeček will focus on in his upcoming post on application analysis.
This is a machine translation. Please excuse any possible errors.


