Serverless computing: jde to i bez serverů!

Jak funguje serverless computing? Jaké jsou jeho výhody, nevýhody a čím se liší od služeb PaaS?
Martin Gavanda
Jak by se vám líbilo provozovat aplikace bez starostí o jakoukoliv serverovou infrastrukturu, mít možnost reagovat na výkonnostní špičky v řádu sekund (nebo i méně) a za to vše platit na základě reálného využití jednotlivých služeb? Služby typu serverless computing toto vše umožňují. Už žádné servery!
Tedy bez serverů to samozřejmě nejde, ale z pohledu uživatele jsou servery skryté, nic za ně neplatíte, a hlavně se o ně nemusíte starat. Serverless computing je relativně nový přístup pro provoz určitých druhů aplikací, který vychází z konceptu platform as a service (PaaS) a posouvá jej ještě o krůček dále z pohledu dynamičnosti a flexibility provozu jednotlivých aplikací.
Co je to serverless computing
Zjednodušeně se dá říct, že serverless computing je o poskytnutí určitých platformních funkcí formou pay per use modelu. U standardních infrastructure as a service (IaaS) nebo PaaS služeb typicky platíte za určitou „velikost“ této služby obvykle definovanou výkonem (2 vCPU, 8 GB RAM). V případě serverless computingu naopak platíte za „objem“ využití dané služby:
- jak často spustíte nějakou business funkci,
- kolik milisekund procesorového času spotřebuje jedno spuštění vaší aplikace,
- jaký počet zpráv si vaše aplikace vyměnily,
- kolik zdrojů vaše aplikace využila.
V kontextu Cloud computingu se tedy můžeme setkat se zkratkou FaaS, tedy Function as a Service.

V dnešní době je možné formou serverless computingu čerpat různé druhy služeb:
- Služby pro běh aplikací, kódu či dokonce Kubernetes
- Databázové služby, jak standardní relační databáze, tak objektové
- Rozdílné integrační služby, notifikační služby, služby pro zpracování front nebo API
- AI a machine learning, rozpoznávání textu, analýza videa či dokonce interaktivní chat služby
Serverless computing si tak můžeme představit jako pool zdrojů, které jsou mi k dispozici, a pokaždé, když nějaké zdroje využiji, tak za ně zaplatím.
Základní rozdíly oproti službám PaaS
Služby serverless computing a platform as a service jsou si v mnohém podobné. V obou případech odpadá starost o „podkladovou infrastrukturu“. V obou případech se nemusíte starat ani o operační systém a middleware. Z mého pohledu je tím nejzásadnějším rozdílem model platby za využití služby a dynamika serverless služeb.
Příklad 1: Aplikace
Standardní PaaS
V případě využití standardních PaaS služeb pro provoz aplikací (například Azure Web Apps nebo AWS Elastic Beanstalk) vždy platíte paušálně za podkladovou velikost infrastruktury (standardně nějaký ekvivalent počtu CPU a paměti).
Musíte znát vaši aplikaci, její výkonnostní charakteristiky a na základě toho poté vyberete optimální velikost podkladové instance. Zároveň je nutné brát v potaz architekturu aplikace a adekvátně tomu přizpůsobit další návazné služby a technologie (jako je Load Balancing), horizontální škálování a podobně.
Serverless computing
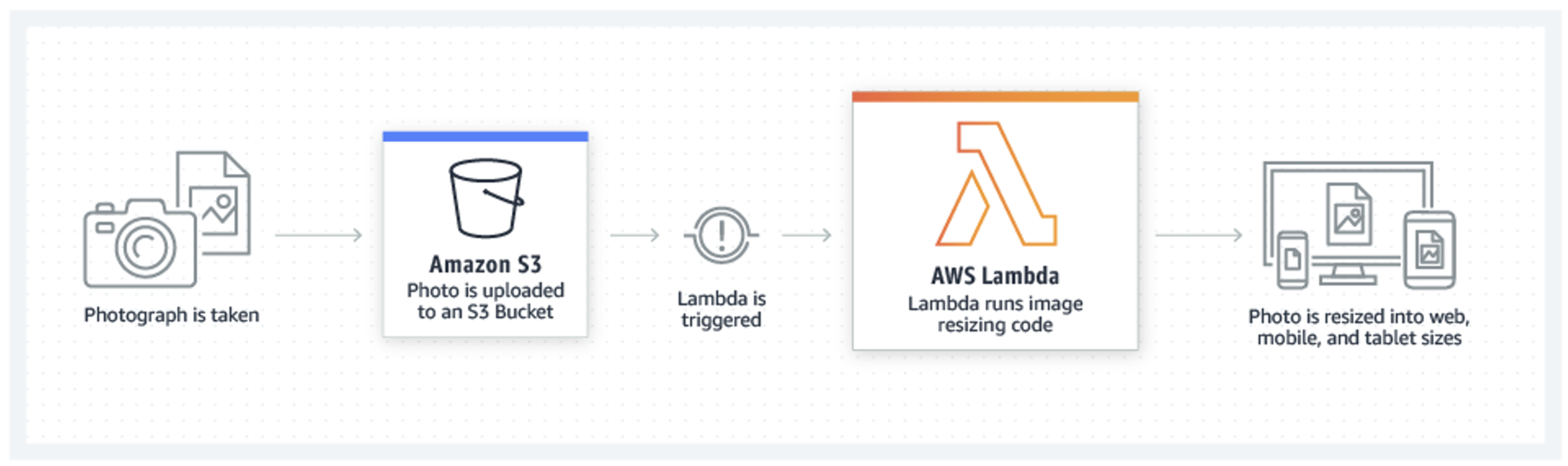
Pokud se rozhodnete využít serverless computing, typicky využijete službu Azure Functions či AWS Lambda, kdy platíte za vykonání (spuštění a provedení) konkrétní funkce. Pod funkcí si představme nějakou jasně definovanou operaci, například „vezmi obrázek na vstupu, vykonej nad ním nějakou operaci, oznam výsledek jiné funkci a ulož obrázek“.
Je úplně jedno, zda určitou funkci spustíte čtyřikrát za měsíc nebo tisíckrát za vteřinu. Potřebujete znát jediné: jaký výkon je nutný k vykonání této funkce (například CPU výkonem či dostupná paměť) a o nic jiného se nestaráte. Platforma automaticky zajistí dostatečný počet zdrojů pro vykonání funkce a vy zaplatíte pouze za čas, kdy funkce běží (obvykle účtovaný v milisekundách).
Abych byl ještě konkrétnější, tak například AWS Lambda je účtována na základě „počtu volání“ funkce (0,2 $ za každý 1 milion) a alokované „časopaměti“ (například 0,0000000333 $ za 1 ms při alokaci 2 GB RAM).
Co to tedy znamená v nákladech? Pokud vaši funkci voláte 5× za vteřinu konstantně po celý kalendářní měsíc, zaplatíte 2,59 $. Zpracování funkce trvá 50 ms. To dá ve výsledku dalších 1,94 $. Dohromady tedy zhruba 4,5 $ za měsíc. Protože AWS Elastic Beanstalk (instance o velikosti t2.small) by vás vyšla na zhruba 19 $ měsíčně, AWS Lambda je v tomto konkrétním příkladu zhruba 4× levnější.
Příklad 2: Relační databáze
Standardní PaaS
V tomto případě je opět nutné definovat „velikost“ instance samotné databáze a tento výkon je zákazníkovi přiřazen. Pokud jej vaše aplikace nevyužije, je to promarněná investice. Naopak, pokud dojde k situaci, kdy by aplikace potřebovala vyšší výkon, není úplně jednoduché na tuto situaci reagovat a „škálovat“ databázi za běhu. Ano, možnosti existují, ale není to triviální a vaše aplikace na to musí být připravena.
Serverless computing
Pokud má vaše aplikace variabilní nároky na výkon, které se v čase dramaticky mění, je možná ideální využít serverless databáze, například Azure SQL Database nebo AWS Aurora. Rozhodně nezapomeňte detailně prostudovat dokumentace jednotlivých sužeb, protože serverless varianta není dostupná pro každý typ databázového engine či pro specifickou konfiguraci.
U serverless databáze opět platíte za alokaci konkrétního výkonu v čase. Kupříkladu v případě Azure SQL Database v módu serverless platíte za každý vCore (procesorová jednotka) 0,0001345 € za sekundu využití.
Samozřejmě můžete definovat minimální a maximální potřebné výkonnostní hodnoty, a dokonce lze stanovovat, zda se databázová služba může dočasně pozastavit, když není využívána. Vaše databáze poté dynamicky alokuje dostatečný počet vCore tak, abyste byly schopni dosáhnout optimálního výkonu.
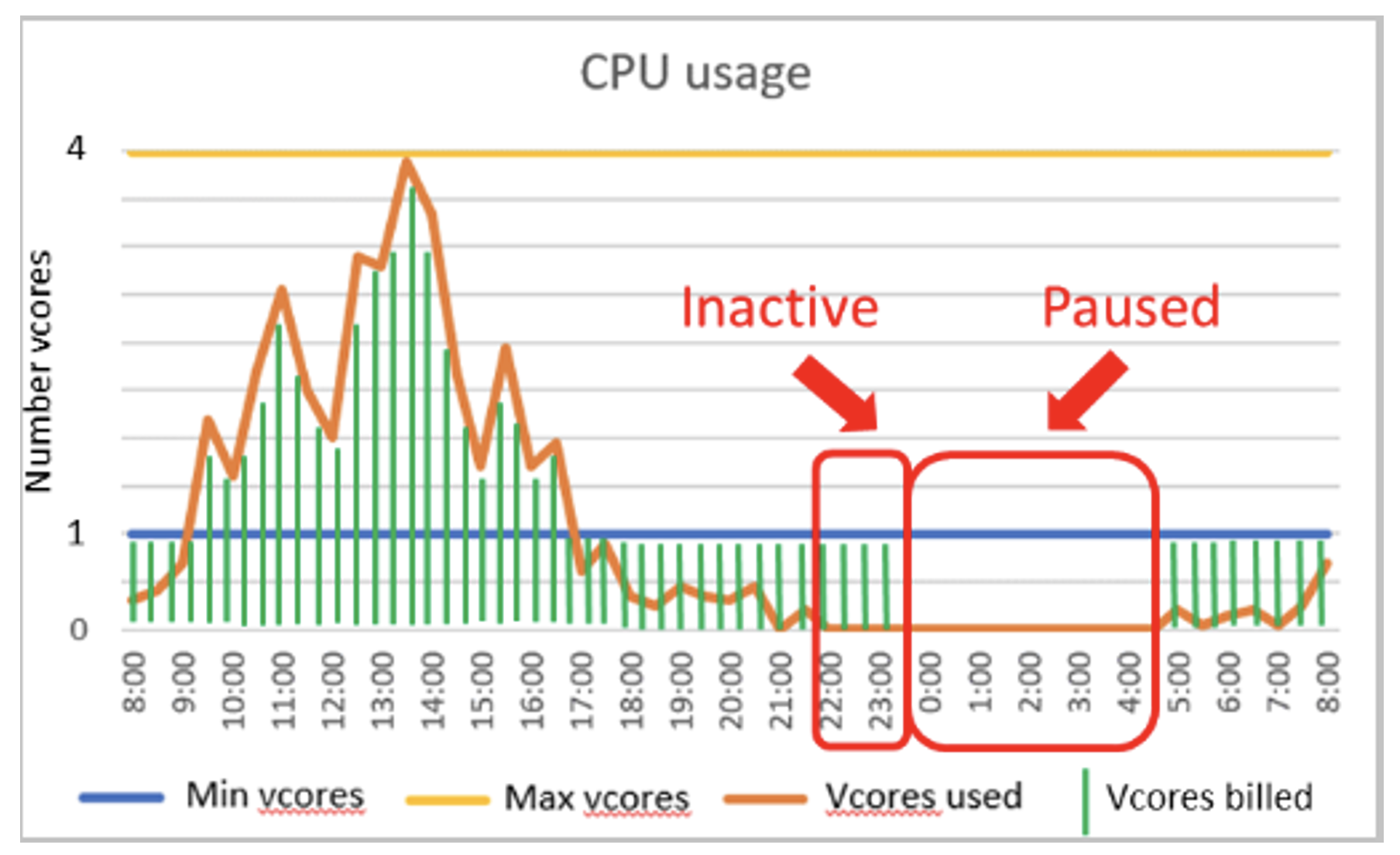
Porovnejme opět náklady. Dva vCores poskytované v PaaS „provisioned režimu“ stojí v Azure SQL přibližně 356 EUR měsíčně. V režimu FaaS stojí stejná databáze 0,5218 $/vCore-hour. Pokud ji využíváme v pracovních době v průměru na 1 vCore, patrně obdržíme fakturu na něco přes 100 EUR při zachování stejných výkonnostních parametrů.
Není všechno zlato, co se třpytí
Jak už to tak u technologií bývá, vždy budou existovat výhody i nevýhody, a je tedy nutné zvážit, kdy je pro vás konkrétní technologie vhodná. Pro serverless computing to platí také.
Z mého pohledu vnímám u serverless computingu tři hlavní nevýhody:
- Musím detailně znát svou aplikaci a její nároky na výkon, což nemusí být vždy jednoduché určit. Pokud moje aplikace nemá výkonnostní špičky a je zatížena konstantně, bude serverless computing pravděpodobně dražší než standardní PaaS či IaaS služby.
- Formou serverless computingu není možné provozovat všechny aplikace, například se nehodí pro monolitické Java aplikace.
- Musím znát veškeré nuance jednotlivých serverless služeb, neboť jak se říká: „Ďábel bývá skryt v detailu“. Ruku v ruce s flexibilitou vždy přijde určitá svázanost platformy. Ať už se jedná o různá „minima-maxima“ nebo omezení konkrétní technické implementace.
Pro jaké aplikace serverless computing použít?
Protože je serverless computing relativně nová forma poskytování služeb, je vhodná primárně pro nově vyvíjené aplikace. Jistě najdeme i scénáře, kdy může dávat ekonomický smysl komplexní refaktoring stávající aplikace (zejména aplikace s velmi variabilními požadavky na výkon).
Obecně bych tedy serveless computing využil primárně pro nově vyvíjené aplikace, kde při správné implementaci můžete docílit de facto neomezených možností z pohledu škálování a výkonu za velice příznivou cenu.
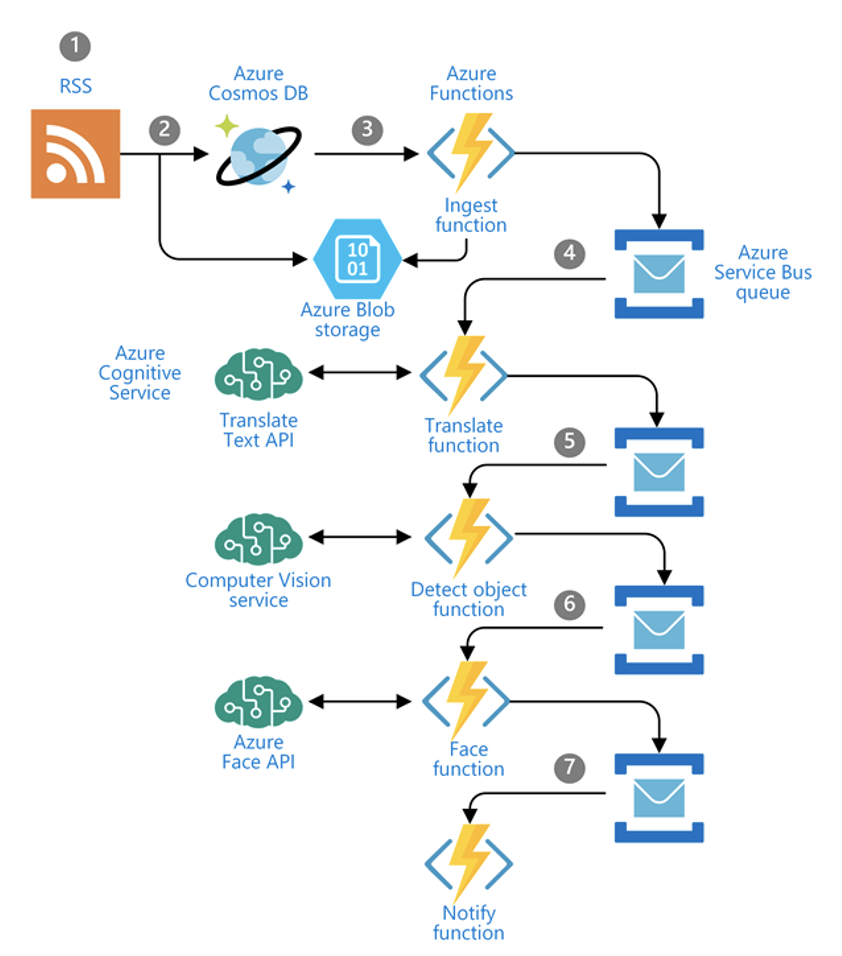
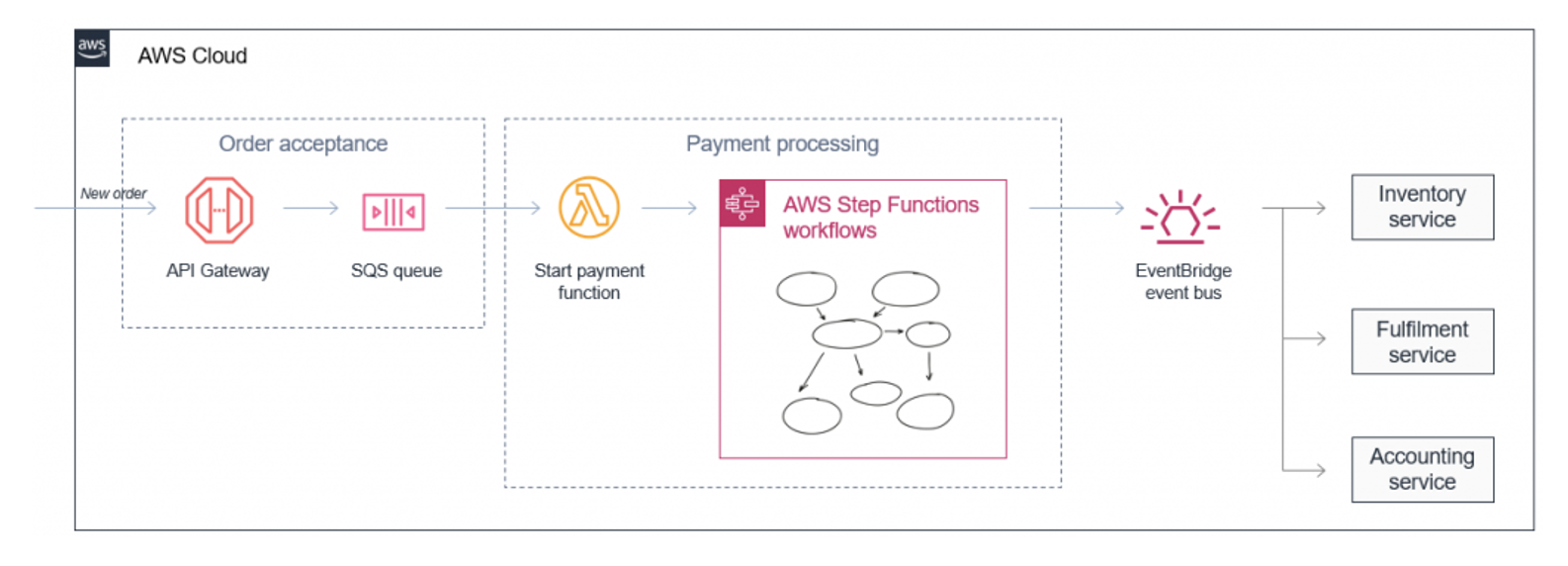
S tímto přístupem se zároveň pojí i jiný koncept aplikační architektury, takzvaný event-driven přístup. Dříve aplikace „prostě běžely“ a byly „kdykoliv komukoliv k dispozici“. Event-driven architektura vychází z předpokladu, že „reaguji na událost“.
Máme tedy typicky producenty těchto eventů (něco se stalo; uživatel nahrál obrázek, došlo ke spuštění business transakce, změna stavu účtu, dorazila nová objednávka).
Poté existují komponenty event routers, které jsou odpovědné za směrování zpráv jednotlivým odběratelům (kdo by o tom měl vědět; pokud existuje nový obrázek, je třeba provést to a to, novou objednávku je třeba zpracovat těmito návaznými aplikacemi).
Posledním článkem řetězu jsou samotní zpracovatelé (consumers). Ti jsou zodpovědní za vykonání určité akce na základě konkrétního eventu (co se má udát; pokud dorazil nový obrázek, je třeba provést určité operace, nová objednávka znamená její zpracování a zanesení do ERP systému).
Serverless computing: Ano, nebo ne?
Serverless computing není vhodný pro každou softwarovou implementaci, ale čím více jsou mé aplikace „cloud native“ a jsou vyvíjeny pro cloud prostředí, tím větší potenciál benefitů mi serverless computing nabízí.
Při správném využití serverless computingu může být má aplikace ve výsledku mnohem robustnější, levnější a dostupnější než v případě klasických PaaS služeb.
Jak se tedy rozhodnout, pro jaké aplikace využít tu kterou službu a technologii? Na to se zaměří kolega Lukáš Hudeček v jeho nadcházejícím příspěvku věnujícímu se analýze aplikací.



