
Compute-intensive and legacy applications require a specific approach before migrating to the cloud. Why is it worth it?

When planning a migration to the cloud, you sometimes encounter applications that will not perform satisfactorily on commonly used compute resource plans (vm sizes, instances, …). These are applications with an earlier date of creation (legacy), applications that are not optimized, or, on the contrary, with code that is optimized – but for the existing on-premise environment. How to solve such problems?
Tomáš Krčma
High power consumption and cooling of fast processors
For legacy single-threaded applications, it is not uncommon to require the highest possible CPU clock speed. However, you will usually encounter this in the large datacenters of cloud providers. In fact, the high power and cooling requirements of processors clocked over 3 GHz do not sit well with high-density datacenter computing environments.
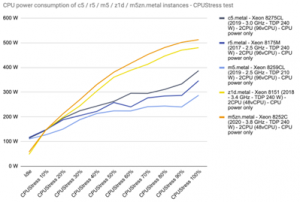
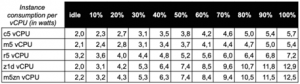
CPUs with high clock speeds are therefore not energy efficient. Even a datacenter architecture that runs on fewer, albeit very powerful, processor cores will not be advantageous for typical operation in the form of a concurrency of many less demanding applications.
The result of migrating a more demanding legacy application to regular cloud computing resource plans can result in at least a slowdown of the application, resulting in economic losses and dissatisfaction of users and management of the organization.
How to migrate legacy and compute-intensive applications to the cloud
To avoid these scenarios, the key (as always) is to prepare the entire migration well. After we identify legacy and other problem applications, we can prepare them to run in the cloud, or prepare the cloud to run them:
- modify the application architecture (or transfer the necessary functionality and data to another application),
- choose one of the special computing plans (or use dedicated hardware).
Modifying the application architecture
The architecture of the application can be influenced at the configuration level or in the code itself.
Modifying an application at the configuration level
We have to make do with this method especially for “ready-made” applications. More modern multi-tier applications that are ready for performance scaling have an advantage.
We replaced the “super-performance” server from the on-premise environment processing the requests of the web application of the ERP system with two servers in the cloud with the help of a load-balancer, and we reserved the third server for servicing requests from outside the network. Side benefits include increased solution redundancy, future scalability, and protection of the internal operations of the organization in the event of a cyber attack.
Changes in the application code itself
This way of influencing the application architecture is usually more complicated than reconfiguration, if it is possible at all. We are usually not allowed to interfere with “finished” applications, but we can work with the software manufacturer on a solution.
In the case of the DMS solution aimed at the public sector, the transition to the Linux version, which was able to work better with parallel processing of tasks in modern processors, helped. In addition, access via mobile devices, which was not possible until then, was a benefit.
In “custom” line-of-business applications, the possibilities are wider. We have the code and we can edit it. A common way is to try to parallelize the program code. This is a demanding discipline where complicated errors can occur due to the complexity of managing the concurrency of application threads.
The third way
But it is not always necessary to resort to costly development. In addition to their own logic, applications usually rely on a number of ready-made libraries, whose newer versions often contain parallelized code that we can just deploy after proper testing.
It is also a good idea to monitor other computing resources so that the bottleneck does not become e.g. memory throughput or disk subsystem, whose performance can be influenced in the cloud by choosing the right tier.
An “extreme” modification of the application may be to convert it to code that can run efficiently on GPUs instead of CPUs, i.e. graphics card processors. This is already a relatively narrow solution. However, large cloud providers have compute plans that include renting the power of AMD or nVidia graphics cards. This approach is suitable for massively parallel operations, machine learning and AI.
The radical cut then is to abandon the “problematic” (usually legacy) application. It can be replaced, for example, by incorporating the functionality of another application that has not yet been used, which will also consolidate the organization’s information system. Another good inspiration can be a cloud provider’s marketplace offering.
We have repeatedly succeeded in moving various personnel agendas, records of equipment loans or management of simpler projects to M365 applications. This eliminated a number of “small systems” with problematic database access solutions (popular retrieval of records one by one), working with a single list and user groups in Azure AD. It has also usually simplified access from different types of devices.
Special compute plans for legacy and demanding applications
Cloud providers are reluctant to deploy high-performance hardware in their datacenters, or they pay well for it (for the reasons mentioned above).
Even if you can’t optimize (especially) a legacy application, there are still ways to run it successfully in the cloud. This is done with special computing plans aimed at applications requiring high processor performance, above-standard amounts of operating memory, etc.
Azure
In an Azure environment, in terms of CPU performance, these are virtual machine sizes:
- Fsv2-series – with Intel Xeon processors clocked at 3.4 to 3.7 GHz,
- FX-series – with Intel Xeon processors clocked at 4 GHz.
These two and many other Azure plans have interesting features, which can be seen, for example, in this document.
AWS
In the AWS environment, these are EC2 instance types in terms of processor performance:
- C7g, C6g, C6gn – with AWS Graviton ARM processors,
- C6i, C6a, Hpc6a– with third-generation Intel Xeon Scalable and AMD EPYC processors clocked at 3.5 to 3.6 GHz,
- C5, C5a, C5n – older generations of Intel Xeon and AMD EPYC processors with an average clock speed of 3.5 GHz,
- C4– with Intel Xeon E5-2666 clocked at 2.9 GHz.
Details of the wide range of AWS plans can be found here, for example.
However, after calculating the longer-term costs of running applications in compute-intensive plans, we can conclude that the costs increase disproportionately compared to running them on-premise.
The global datacenter networks of the major cloud providers are divided into regions (see previous Cloud Encyclopedia article), and not all plans are available everywhere. This may complicate the connection with other parts of the organization’s information system, or the application may not be able to be started after the downtime (due to the lack of these “scarcer” resources in the cloud).
Then it is appropriate to consider one of the options of providingdedicated hardware, which can be customized by the provider. In this way, we take advantage of the high-quality infrastructure of a large datacenter, where we have an optimal computing solution dedicated to our tasks.
Redundancy can be addressed using shared cloud resources if the limited performance is acceptable during a dedicated hardware outage.
Summary: Even legacy and computationally intensive applications can be migrated
Computationally intensive plans are among the more expensive ones in the cloud. Calculate the cost of their deployment in advance – either with the help of cloud calculators, but preferably with the advice of an experienced migration partner.
The expected cost of operation tells you how much it makes sense to spend on optimising or changing your application to run it more cost-effectively. Or whether, especially with a permanent larger volume of demanding calculations, you should try asking for a dedicated solution.
When choosing the final solution, as with all IT projects, we should not forget to look at security, availability and sustainability.


