
Cloud Management 1: Don’t patch, redeploy!

The cloud (whether public nebo private) can be described as a “software-defined datacenter”, by which we mean that all elements of our infrastructure can be managed in software. But we can choose how we approach this. Cloud management can be done the old-fashioned way – manually, or the modern way – software and automation. The following mini-series of articles will be about the latter.
Petros Georgiadis
Manual cloud management is like an uncomfortable iron shirt
Working manually (without automation) in an on-premise data centre is a common uncomfortable iron shirt. Few people have their entire data centre “software-defined”, whereas in the cloud it is like that from the start.
In the cloud, we can also work in a nice old-fashioned way – i.e. manually, slowly, with the risk of introducing human error and with a lot of repetitive activities – starting on the dev environment, proceeding through test, integration test, acceptance test, pre-production test (pre-prod), and finally arriving at the production environment (prod).
However, we often don’t ensure that the pre-prod environments are identical to the production one. This means that we can’t be sure that a task, such as an operating system (OS) upgrade, won’t introduce some change to the system that will be incompatible with your application. Such a situation could result in application failure and subsequent rollback.
Another negative aspect of manual infrastructure management is the considerable labor and time required.

Let me give you an example from a PCI DSS certified environment. The standard requires all operating systems to be patched at least once every three months. If you have 60 servers, updates have to be done at night by two people (infra admin + application specialist – there has to be a different application specialist for each application), which is quite a lot of sleepless nights, stress and wasted money.
When I ask the manager responsible for running the infrastructure if he would like to automate these updates, the answer is that if it makes economic sense, then sure. But I always reply that the point of automation is not just to compare the cost of creating an automated environment with the cost of a human to oversee the updates for the next five years.
The time of IT specialists should be devoted to development instead of laborious maintenance of the environment.
Moreover, IT professionals today choose what kind of work they want to do. And it’s quite possible that in 5 years there will be no one who wants to update operating systems at night. So there’s no need to wait and let’s move on to the other way of working with the cloud.
Modernization of cloud management
All cloud environments (AWS, Azure, GCP, OpenStack, Proxmox, Kubernetes, etc.) can be controlled programmatically using their APIs. Cloud GUIs are built on top of them and any actions we can do via the GUI can be done directly via the API.
However, not all IT professionals are such proficient programmers to call cloud APIs directly from their code. That’s why there are a number of tools that enable this communication for us, such as AWS CLI, Azure CLI, Terraform, kubectl, etc. This is getting very close to the Infrastructure as a Code (IaC) concept that we have already written about in our cloud encyclopedia.
Let’s take a look at what modern cloud management looks like – that is, how we will patch operating systems, platforms, and deploy new versions of applications in the infrastructure created with IaC. We can deploy our IT systems to the cloud via: 1) virtual machine (VM) servers, 2) containers or 3) serverless functions.

1) CLOUD MANAGEMENT & Virtual Servers
As the name implies, a virtual server is a server. And when you say server, the average IT person thinks of something very expensive, large and complex that needs to be taken care of. This premise is indeed true for a physical server, but potentially harmful and limiting in the case of a virtual server.
The real value of a VM is in its functionality and the data it contains. Ideally, persistent data should not be stored directly on the VM, but on some external storage or database.
We should associate the functionality of a VM with the application that performs that functionality rather than with the server itself. The implication is that a VM is just something that allows us to run the application and connect it to the application data and to the outside world.
Pets vs. cattle
So why are there virtual servers that have been running for many years, have a name, a static IP address (which everyone on the team knows) and IT administrators sit up nights to keep them in good shape?
This is because it is not trivial to completely (manually) install, configure and test a virtual server. So once the job is done, it is easier to install upgrades and new versions of the application than to throw it all away and start from scratch. And so we take care of our virtual servers like pets.
Creating and testing installation scripts is not trivial either. But it is true that once we’ve been through it once, the subsequent reusability is far greater than with a manually installed VM.
So once we have automated virtual server installations, we can “plant new VMs like Bata drills”. It doesn’t matter if we create one, three or ten virtual servers. And we don’t even have to think twice about what to do with an outdated VM – we just throw it away and replace it with a new one.
Golden image vs. bootstraping
A virtual server is normally started from an image. Usually, it starts from a base image that contains a specific version of the operating system. Then the necessary platforms (e.g. Java) and applications are installed. The resulting virtual server can be saved as a new image, which is then used to start the VM. A fully installed image is called a golden image.
In cloud environments, we also have the option to automatically install the necessary platforms and applications right after the server starts using cloud init scripts. This is called server bootstrapping.
-
- The advantage of using a golden image is the fast start of a new VM. The disadvantage is a more complex process of upgrading individual components and creating a new image. A prerequisite for efficient use of the golden image is the existence of a CI/CD pipeline that automates the creation of new versions.
- – If you do not have such a CI/CD pipeline, use server bootstrapping instead. In this case, the server takes longer to boot (on the order of minutes) and you must resist the temptation to update the operating system immediately after boot (e.g., with sudo yum update). Also, be sure to define specific versions of all components that you install at boot time (see the image).
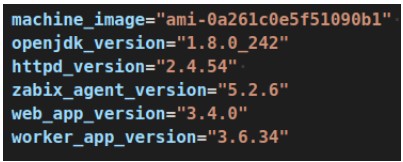
It is good practice to keep the pre-pro and production environments identical. The installed versions of each component should differ only in their configuration – that is, the configuration should never be part of the image, but should be downloaded externally.
For example, you can take inspiration from the tutorial on how to build cloud apps at The Twelve Factor App.
Autoscaling
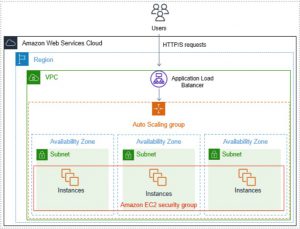
If we can easily create a new virtual server, how can we make sense of it? Cloud environments provide us with Platform as a Service (PaaS) platforms that do a lot of things for us, which is the main reason we consider using the public cloud.
A virtual server that you start in the public cloud will not be cheaper than one that you run on your own physical server. On the other hand, the public cloud offers us options that would be very difficult to achieve on our own – for example, automatically starting our virtual server in one of the nine available datacenters within a region.
To open the door to these opportunities, your app must meet two basic conditions:
- You must not store persistent data on the local disks of the virtual server.
- You must not care whether a particular VM instance is running or not – that is, VMs are interchangeable, and you can add and remove them as needed.
Once both conditions are met, you can use e.g. auto scaling groups, which provide the following benefits:
-
- they keep track of the minimum required number of healthy VMs,
- remove VMs that fail the health check,
- add and remove VMs according to their current utilization based on various metrics (e.g. CPU usage, RAM usage, number of requests directed to a VM),
- automatically register/de-register VM instances in the load balancer,
- in case of datacenter failure, start missing VMs in the remaining available datacenters,
- ensure that new versions are deployed without system failures (in connection with the load balancer).
2) CLOUD MANAGEMENT & Containers
Containers are a much younger technology than server virtualization, and thus far better suited to today’s automated age.
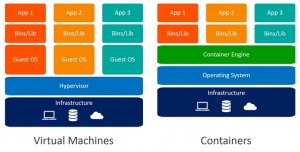
In the following figure, you can see that each virtual server contains its own operating system, libraries, and applications, whereas a container contains only libraries and applications. (This makes a typical VM image tens of GB in size, whereas a typical container image is only hundreds of MB in size.)
Fortunately, the concept of container technology warns users that the lifetime of a container can be in the order of minutes. Therefore, there is no point in plugging in and doing some manual intervention.
I’d almost say that the idea of VM instance expendability came from the container world, and it’s an example of how a newer technology helped modernize a previous one (kind of like how snowboards inspired the creation of carving skis, and today we use both).
Container image
Just as there are VM images, there are container images. But with one major difference: the container image should always be a golden image, i.e. it should contain all the necessary libraries and versions of the application. (Purely theoretically, we could install something after the container starts, but this idea seems “vulgar” to me, so I won’t even explore it further.)
Containers should start very fast (within seconds), which you can only achieve with a ready-made image. Then upload this to a repository (e.g. Nexus and jFrog in an on-premise environment, or Docker Hub, AWS ECR, Azure CR in cloud services) from where you can easily distribute your application and its different versions.
Container management platforms
We need to run containers on some kind of container engine. Docker Engine or Docker Compose are only suitable for local development and testing, but not for running applications.
For production deployment of a container they are used:
-
- open source Kubernetes (k8s), which you can run on-premise, in the cloud, or buy as a service (PaaS) from a number of different providers,
- proprietary solutions from public cloud providers (e.g., AWS ECS, Azure Service Fabric, Google Cloud Run, and others) that tend to integrate very well with other cloud services.
If you decide to run a container platform yourself, you will most likely do it on virtual servers. Therefore, keep in mind that you should automate the actual deployment of this platform, as we described in Virtual Servers.
3) CLOUD MANAGEMENT & Serverless features
A serverless function is basically code in a programming language + the necessary libraries of that language. These functions are mainly associated with public cloud providers (e.g. AWS Lambda, Azure Functions, GCP Functions), but we can also find kubernetes projects that allow us to run serverless functions in our k8s cluster (e.g. kubeless, knativ or fn).
What’s worth noting is that the libraries we use in our functions may contain vulnerabilities that we should know about and should be able to fix without much effort by upgrading the library to a higher version.
Now that I’ve mentioned vulnerabilities in libraries, I’m sure a few more lines could be written about vulnerability scanning, how to deploy patches using the CI/CD pipeline, how to work with IaaC scripts, and how to tie it all together into one end to end process. Modern cloud management is a big topic, so we’ll save some for next time.
Good advice in the end: don’t patch, redeploy!
The practices I describe in this article have been proven over many years and by thousands of companies around the world. You will find a number of detailed technical articles and tutorials on the subject. So, in short:
- Don’t be afraid of change – we’re not doctors, so if we make a mistake, nobody dies. (The advice is only for those who don’t run mission-critical IT systems.)
- Don’t dig your field with a spade, get a tractor!
- Have big plans, but feel free to start with small steps.
- If you don’t know what to do, contact us. We’re happy to help with topics other than cloud management.


