Výpočetně náročné a legacy aplikace vyžadují před migrací do cloudu specifický přístup. Proč se vyplatí?

Při plánování migrace do cloudu občas narazíte na aplikace, které na běžně používaných plánech výpočetních prostředků (vm sizes, instances, …) nebudou dosahovat uspokojivého výkonu. Bývají to aplikace dřívějšího data vzniku (legacy), aplikace neoptimalizované, nebo naopak s kódem optimalizovaným – ale pro stávající on-premise prostředí. Jak takové problémy řešit?
Tomáš Krčma
Vysoká spotřeba energie a chlazení rychlých procesorů
U legacy jednovláknových aplikací není žádnou vzácností požadavek na co nejvyšší takt procesoru. S tím však ve velkých datacentrech cloudových poskytovatelů obvykle narazíte. Vysoké energetické nároky na napájení a chlazení procesorů s taktem přes 3 GHz se totiž s prostředími vysoké hustoty výpočetního výkonu datacenter nemají příliš rády.
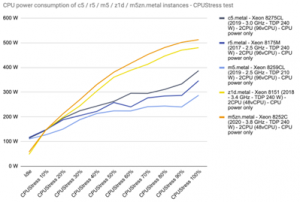
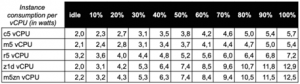
CPU s vysokými takty tedy nejsou energeticky efektivní. I architektura datacentra, které poběží na menším počtu byť velmi výkonných procesorových jader, nebude výhodná pro typický provoz v podobě souběhu mnoha méně vytěžujících aplikací.
Výsledkem migrace náročnější legacy aplikace do běžných plánů výpočetních prostředků cloudu tak může být přinejmenším zpomalení běhu aplikace, z toho plynoucí ekonomické ztráty a nespokojenost uživatelů a managementu organizace.
Jak migrovat legacy aplikace a výpočetně náročné aplikace do cloudu
Abychom těmto scénářům předešli, základem je (jako vždy) kvalitní příprava celé migrace. Poté, co legacy a jiné problémové aplikace identifikujeme, je můžeme připravit na provoz v cloudu, nebo na jejich provoz připravit cloud:
- upravíme architekturu aplikace (případně přeneseme potřebné funkcionality a data do jiné aplikace),
- zvolíme některý ze speciálních výpočetních plánů (případně využijeme dedikovaného hardwaru).
Úprava architektury aplikace
Architekturu aplikace lze ovlivnit na konfigurační úrovni, nebo v samotném kódu.
Úprava aplikace na konfigurační úrovni
S tímto způsobem si musíme vystačit zejména u „hotových” aplikací. Výhodu mají modernější vícevrstvé aplikace, které bývají na výkonové škálování připravené.
„Supervýkonný“ server z on-premise prostředí zpracovávající požadavky webové aplikace ERP systému jsme v cloudu nahradili s pomocí load-balanceru dvěma servery a třetí jsme vyhradili obsluze požadavků z vně sítě. Vedlejšími benefity je zvýšení redundance řešení, škálovatelnosti do budoucna a ochrana interního chodu organizace v případě kybernetického útoku.
Změny v samotném kódu aplikace
Tento způsob ovlivnění architektury aplikace bývá oproti rekonfiguraci složitější, pokud je vůbec možný. Do „hotových“ aplikací obvykle nesmíme ani nemáme jak zasahovat, nicméně na řešení lze spolupracovat s výrobcem softwaru.
U DMS řešení zaměřeného na veřejný sektor pomohl přechod na linuxovou verzi, která dokázala lépe pracovat s paralelním zpracováním úloh v moderních procesorech. Přínosem byl navíc přístup přes mobilní zařízení, který do té doby nebyl možný.
Ve „vlastních“ line-of-business aplikacích jsou možnosti širší. Máme k dispozici kód a můžeme jej upravit. Častou cestou je snaha o paralelizaci programového kódu. Jde o náročnou disciplínu, kdy může docházet ke komplikovaným chybám kvůli náročnosti řízení souběhu vláken aplikace.
Třetí cesta
Ne vždy je ale nutné sáhnout k nákladnému vývoji. Aplikace kromě vlastní logiky většinou spoléhají na celou řadu hotových knihoven, jejichž novější verze paralelizovaný kód často obsahují a které můžeme po řádném otestování pouze nasadit.
Je dobré monitorovat i ostatní výpočetní prostředky, aby se úzkým hrdlem nestala např. prostupnost paměti nebo diskový subsystém, jehož výkon můžeme v cloudu ovlivnit volbou správného tieru.
„Extrémní“ úpravou aplikace může být převod do kódu, který půjde efektivně spouštět na GPU místo CPU, tedy na procesorech grafických karet. Jedná se již o poměrně úzkoprofilové řešení. Velcí poskytovatelé cloudu mají nicméně výpočetní plány, které pronájem výkonu grafických karet AMD nebo nVidia zahrnují. Tento přístup je vhodný pro masivně paralelní operace, strojové učení a AI.
Radikálním řezem pak je „problematickou“ (obvykle legacy) aplikaci opustit. Nahradit ji můžeme například zapojením dosud nevyužívané funkcionality jiné provozované aplikace, kdy zároveň dojde ke konsolidaci informačního systému organizace. Další dobrou inspirací může být nabídka na marketplace cloudového poskytovatele.
Opakovaně se nám daří různé personální agendy, evidence zápůjček vybavení či řízení jednodušších projektů přesouvat do aplikací prostředí M365. Odbourala se tak řada „drobných systémků“ s problematickým řešením přístupu k databázi (oblíbené načítání záznamů po jednom), pracuje se s jedním seznamem a skupinami uživatelů v Azure AD. Obvykle se i zjednodušil přístup z různých typů zařízení.
Speciální výpočetní plány pro legacy a náročné aplikace
Cloudoví poskytovatelé se nasazování velmi výkonného hardwaru ve svých datacentrech brání, respektive si ho (z důvodů zmíněných výše) nechají dobře zaplatit.
I když se nepodaří (zejména) legacy aplikaci nijak zoptimalizovat, stále existují cesty, jak ji v cloudu úspěšně provozovat. Slouží k tomu speciální výpočetní plány zaměřené na aplikace požadující vysoký výkon procesoru, nadstandardní objem operační paměti apod.
Azure
V prostředí Azure se z hlediska výkonu procesoru jedná o virtual machine sizes:
- Fsv2-series – s Intel Xeon procesory taktovanými na 3,4 až 3,7 GHz,
- FX-series – s Intel Xeon procesory taktovanými na 4 GHz.
Tyto dva i mnohé další Azure plány mají zajímavé vlastnosti, s nimiž se lze seznámit například v tomto dokumentu.
AWS
V prostředí AWS se z hlediska výkonu procesoru jedná o EC2 instance types:
- C7g, C6g, C6gn – s AWS Graviton ARM procesory,
- C6i, C6a, Hpc6a – s třetí generací Intel Xeon Scalable a AMD EPYC procesorů s taktem 3,5 až 3,6 GHz,
- C5, C5a, C5n – starší generace Intel Xeon a AMD EPYC procesorů s taktem v průměru 3,5 GHz,
- C4 – s Intel Xeon E5-2666 s taktem 2,9 GHz.
S podrobnostmi pestré nabídky AWS plánů se lze seznámit například zde.
Po propočítání dlouhodobějších nákladů na provoz aplikací ve výpočetně intenzivních plánech ale můžeme dojít k závěru, že se náklady oproti provozu v on-premise nepřiměřeně zvýší.
Globální sítě datacenter velkých cloudových poskytovatelů se člení do regionů (viz předchozí článek Encyklopedie cloudu) a ne všude jsou všechny plány dostupné. Může to komplikovat propojení s dalšími částmi informačního systému organizace, případně se nemusí podařit aplikaci po odstávce spustit (pro nedostatek těchto „vzácnějších“ prostředků v cloudu).
Tehdy je namístě zvážit některou z variant zajištění dedikovaného hardwaru, který může být poskytovatelem sestaven i na míru. Využijeme tak kvalitní infrastrukturu velkého datacentra, kde máme k dispozici optimální výpočetní řešení pro naše úlohy, které je vyhrazené jen pro ně.
Redundanci můžeme řešit s využitím sdílených cloudových prostředků, pokud je omezený výkon po dobu výpadku dedikovaného hardwaru přijatelný.
Shrnuto: I legacy a výpočetně náročné aplikace můžeme migrovat
Výpočetně intenzivní plány patří v cloudu mezi ty nákladnější. Cenu jejich nasazení si předem propočítejte – buď s pomocí cloudových kalkulaček, raději však s radami zkušeného migračního partnera.
Očekávané náklady na provoz napoví, kolik prostředků má smysl vynaložit na optimalizaci či změnu aplikace, abyste ji mohli provozovat hospodárněji. Nebo zda zejména při trvalém větším objemu náročných výpočtů nezkusíte poptat dedikované řešení.
Při volbě finálního řešení nezapomínejme jako u všech IT projektů na pohled z hlediska zabezpečení, dostupnosti a udržitelnosti.



