
Backup in the cloud: why, when, what and, most importantly, how?
Your data in the cloud is not automatically protected. Why, when, what and especially how to back up in the cloud?
Jakub Procházka
Backing up is like taking paracetamol tablets. You are calmer when you know you have them somewhere, and they can relieve you of unnecessary distress when needed. Just as with tablets, we have to keep an eye on the expiration date, so too with backups we check that they are done regularly and are able to actually restore the data from them at the required time. Let’s take a look at what cloud backup looks like.
Why back up?
We back up data (not only in the cloud) for many reasons and we usually decide how to back it up. The main goal is not to lose data companies in case of an unexpected event. Such events can be:
- Human error leading to data error
- Hardware, software failure
- Natural disasters
- Ransomware, malware and other viruses
- Intentional damage from the inside (inside job)
- Theft and lubrication
- Attacks by hackers or crackers
I deliberately list human error here in the first place because it is clearly the most common cause of most major and minor reasons for data recovery.
In a cloud environment, we are not automatically more protected! Backups are not enabled by default and we have to secure data sources according to the same logic as in a regular datacenter.

Back up, back up, back up…
Backup is an important part of any business operation. However, each company approaches it slightly differently, as it has its own specific requirements based on technical, commercial, operational or legislative/policy aspects. Therefore, it is not possible to formulate any universal recommendation, but it is necessary to perceive the overall context of the company and the specific data.
The following requirements, for example, may affect the backup method:
- Certification standards (e.g. ISO)
- Legislative regulation (e.g. CNB regulation, GDPR)
- Limiting operation and maintenance costs
- Other technical and business requirements
As with most other major cloud disciplines, it is advisable to think and plan the target concept first. This activity may be called defining a backup strategy and is often part of a Business Continuity Plan (BCP).
The topic of today’s article is not BCP, data security or disaster recovery (DR), so I will try to focus on the backup itself.

Schrödinger backup
Very often I see that a company sets up cloud backups at the beginning, but then doesn’t care much about them. In the best case, notifications are set when a backup job is not executed. I call such backups Schrödinger backups – because until you actually try to restore from them on D-Day, you don’t know if the backups are of any use.
Although these situations can be thrilling or even exciting, I recommend avoiding them. Backups are meant to be a security you can always rely on– it’s Plan B. Plan C, which is what happens in the event of missing advances, is usually not at all pleasant and is difficult to explain not only to management but also, for example, to an auditor who has come for an inspection by a regulator such as the CNB.
Even backups that seem fine at first glance may be corrupted, infected in some way (e.g. ransomware), or the backup job runs, but the backup is null or incomplete (tool error, wrong settings, configuration or permissions change). A possible backup of a backup is then also unusable, namely that it lies logically and physically e.g. in another zone won’t save us.
Therefore, in addition to notifications from the backup tool about the execution (or not) of the backup job, it is advisable to periodically checkthe backups and perform a test restore. These tests should prove, among other things, that the solution meets the required RTOs and RPOs set for the data content according to the agreed application service level.
- RTO – Recovery Time Objective – the ability to recover within a specified time
- RPO – Recovery Point Objective – the ability to recover to a specific point
Backups should be the responsibility of a specific person (or group of persons) who oversees compliance with the requirements arising from the company’s strategy. This monitoring should include verifying the recoverability of critical backups and related processes at regular intervals at least once every six months, but no more than once a year.

Backup (not only) in the cloud
In this article, we focus primarily on cloud backup, but the principles of backup remain the sameregardless of whether you are backing up pure cloud data (Azure, AWS, GCP), multi-cloud or hybrid cloud.
In all cases, claims should be consistent. Backup needs should be clearly defined by the company and not limited to a specific environment. This is why most major backup software supports multiple environments and allows you to link different sources and targets for backups.
Integration is usually done either directly by a connector or the backup service provider offers its own variant of the cloud solution, for example in the form of an appliance.
What to back up in the cloud?
In the cloud, we divide backup into three basic categories: IaaS, PaaS, SaaS. PaaS and SaaS services usually have limited native backup capabilities from the provider, but can often be integrated with external tools (which is often desirable given these limitations). In the case of IaaS, backups can then usually be handled similarly to on-premise (classic virtual machine backup).
Just because your data is running in the cloud doesn’t mean it’s automatically backed up! This common misconception also applies to SaaS. The data is always the responsibility of the customer (see the shared responsibility model in the previous article in the series) and cloud providers leave the backup to the customer. The exception may be some SaaS services, where sometimes the provider makes a partial backup natively.
I recommend always checking the details of the backup with a SaaS solution and deciding whether the solution is sufficient and whether I can rely at all on backups performed by someone else (and thus not explicitly under my control).
For example, Microsoft SharePoint Online is only backed up every 12 hours with only 14 days retention (i.e. I only have data back 14 days). You can request these backups, but Microsoft has 30 days to restore them. Are you happy with this backup scheme?
In addition to the data itself, we must not forget aboutinfrastructure and configuration data in general. Ideally, we should have our cloud architecture defined using Infrastructure as a Code (IaaC) and keep these files backed up, updated and versioned. Thanks to this, we are able to restore not only the data, but the entire operating environment.
What tool to use?
Most customers are already entering the cloud with an existing on-premise solution. If an existing on-premise backup tool supports the public cloud, we can integrate it and use native tools from cloud providers only for unsupported services (if any).
Native backup tools include Azure Backup for the Microsoft cloud, while Amazon offers AWS Backup.The most well-known third-party products that also support public clouds include:
- Veeam
- Commvault
- Unitrends
- Acronis
The functionality of each tool varies and should be reviewed more thoroughly. For startups or companies just getting started with the cloud, a cloud provider’s native tool may be the easiest and most cost-effective option.
How often to back up and where?
Once you’ve chosen a tool, it’s time to decide how often to back up, where to store the backups, and how long to keep them (retention).
The frequency of backups is determined by the criticality of the data resulting from the application business analysis. Determine what RPOs we have and over what time period the company can afford to be missing data. Let’s leave aside the concept of high availability and possible active-passive and other settings for failover.
The golden rule says that we should back up on a 3-2-1 basis, i.e. have three backups at two facilities and one at another location. This is also fulfilled in the cloud, taking into account availability zones and the archive layer.
For production backups, it is probably most common to perform daytime backups at night. Thus, at the end of the day, a backup of the new data (usually incremental) is made and once a week the whole.
Daily backups are most often kept for 30-60 days on high-performance storage – tier hot for Azure, standardfor AWS. After this time, we store only weekly and monthly backups, which we use lifecycle management to move to cheaper and less powerful tier tier storage – cool and then archive in the case of Azure, Standard-IA, Glacier and Deep Archive for AWS.
Archive tier for Azure and Deep Archive for AWS are storage tiers at the level of proven tape cartridges. In this case, we are talking about archiving rather than backup as such. Data on the archive tier is stored very cheaply, but it can take several days to recover.
Whether an incremental or full backup is performed can be influenced in the selected backup software, and some tools may also support data deduplication. Unless we are backing up to our off-cloud disk arrays, we can only affect these functions at the software level, and only deal with individual tiers (layers) at the storage level.
Backup in Azure
Azure is evolving very quickly, so services often change literally under customers’ hands. At the same time, Microsoft (MS) likes to change the names of services and move their functionality between each other. Because of this, the overall backup solution can be stretched across several services with often interchangeable names, worsening the already poor visibility.
MS is becoming aware of this, which is why it has been taking steps in recent months (written in the second half of 2021) to make the whole backup solution simpler and, above all, clearer.
In the area of backup, Azure was inadequate as an overall backup solution for more demanding clients. Now a new service is coming out that has the ambition to change that. This is the Backup Center, which is intended to act as a single pane of glass for backups in Azure. However, until it goes from preview to general availability (GA) it may contain bugs, has no SLA, and can theoretically be withdrawn from the offer.
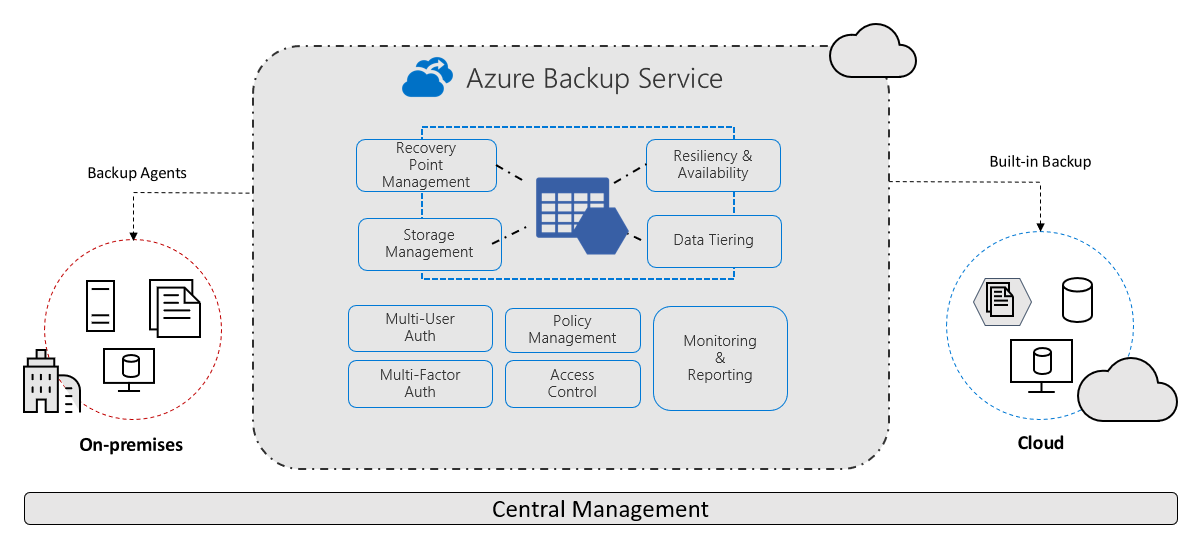
For Azure backups, the Recovery Services vault is a critical component. Official Microsoft documentation defines it as a storage entity in Azure that is used to store data. This data is typically data copies, configuration information for virtual machines (VMs), servers, workstations, and other workloads.
Using the Recovery Services vault, you can make backups for various Azure services such as IaaS VMs (both Linux and Windows) and Azure SQL databases. It makes it easier to organize your backup data and reduces the management effort. Recovery Services vaults are based on the ARM model (Azure Resource Manager), which provides functionalities such as:
- Advanced options for securing backed-up data
- Central monitoring for hybrid IT environments
- Azure RBAC (Role Based Access Control)
- Soft Delete
- Cross Region Restore
Simply put, it is a comprehensive service providing backup, disaster recovery, migration tools and other functionality directly in the cloud.
Azure Migrate, which was previously only used for workload measurement and assesment, is now listed as the primary tool for migration. It now includes tools for the migration itself, which was previously performed separately via Azure Site recovery(ASR) in the Recovery Services vault.
The Recovery Services vault is Microsoft’s preferred option for backup and disaster recovery that is built natively into Azure (sometimes also referred to generically as Azure Backup).
The main advantage of the Recovery Services vault is the ability to back up on-premise workloads and perform failover from on-premise to the cloud as well as from one region to another.
You can back up Azure, Azure Stack, and OnPremise data to the Recovery Services vault.
The list of supported systems with support matrix is available here.
Backup in AWS
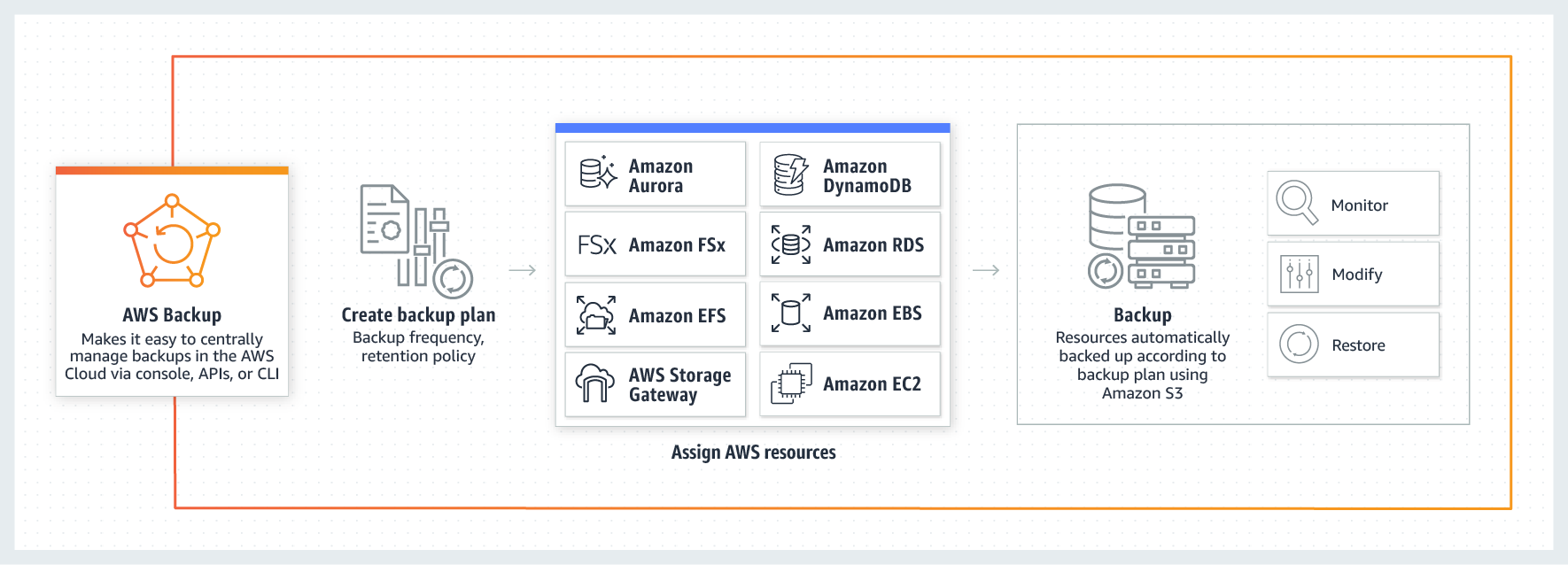
The native tool in AWS is called AWS Backup. The principle is similar to that of competitor Microsoft, it also supports lifecycle management, workload backup running outside of AWS itself (e.g. on-premise) and many other functionalities such as:
- Centralized backup management
- Policy-based backup
- Tag-based backup
- Automated backup scheduling
- Automated retention management
- Backup activity monitoring
- AWS backup audit manager
- Lifecycle management policies
- Incremental backup
For on-premise data backup, you must deploy an AWS storage gateway. Advanced automation tools are definitely one of the strong points of AWS Backup.
If you’re dealing with cloud backup with only one provider, I recommend going the native tool route. For multi-cloud or hybrid cloud architectures, it’s a good idea to consider each tool and explore in more detail the combination that fits your needs.
Conclusion
Don’t wait until you have a problem – be it human error or any other cause.
Conduct restore tests. The cloud is an amazing tool in that you can recover a large portion of your environment, verify the accuracy of the data, and delete the recovered data for very little cost.
And then you can sleep soundly…
The previous 11 chapters of the Cloud Encyclopedia series can be found here.
This is a machine translation. Please excuse any possible errors.


