High availability of services in the cloud - how to do it?

In this Cloud Encyclopedia article, we'll talk about high availability service design, or high availability (HA). How to achieve it, what to assemble it from, how big should it be? What is called high availability - is it 99.5 %, 99.9 % or 99.95 %? And is it just about high availability of cloud services, or do other considerations like disaster recovery come into play? Let's see what options we have in the cloud and what all needs to be taken into account.
Lukas Hudecek
High availability of services - general characteristics and what is SLA
In general, high availability designs are based on business needs, which most companies have defined in business continuity strategies, impact analyses and related SLAs.
When planning for high availability, we must first define how big the availability should be. And we have to assume what happens when part or all of the system fails. It is essential to define all kinds of impacts - operational, financial, customer relationship, overall business impact.
From these definitions, the following are calculated maximum permissible outage times. The basis for the architectural design will be established, which will take into account the required service availability levels, called service-level agreement, hereinafter referred to as SLA.
The SLA defines the parameters of the delivered service, such as its description, operating time, reporting, security parameters, service performance measurement and, most importantly, service reliability and availability. In IT parlance, the SLA XX % usually refers to the percentage of service availability.
For illustration SLA 99.9 % represents the maximum outage time:
- 1 min 26 sec per day
- 10 min 4 s per week
- 43 min 49 sec per month
- 2 h 11 min 29 quarterly
- 8 h 45 min 56 s per year
To achieve high SLAs, it is necessary to define a robust, resilient and reliable architectural design of the application or the entire environment so that all components used as a whole meet the required service level.
In general, the the whole system is as robust as its weakest linkwhich is often the most common problem in an effort to save money.
In addition, we need to design the architecture so that all maintenance tasks count on maintaining SLAs, such as:
- updates and upgrades,
- data recovery in case of damage or hacker attack,
- service and environment deployment (CI/CD).
Impacts of outages
Achieving high availability (i.e., an SLA starting with "three nines": 99.9 %) is not a cheap affair. The SLA value must therefore be based on the processed BIA impact analysis (business impact analysis), which defines the impacts of the outage and the resulting RPO/RTO/MTPOD times that they indicate:
- RPO (recovery point objective) - maximum time of data loss,
- RTO (recovery time objective) - maximum data recovery time,
- MTPOD (max tolerable period of down time) - the maximum recovery time of the entire system, including the corrective steps after data recovery.
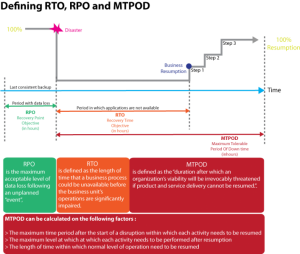
Quantification of the impact
After defining the RTO/RPO/MTPOD parameters, we need to have a quantified impact, i.e. how much it will cost if the systems do not run for e.g. 24/48/72 hours. Only then is the CFO (or someone who holds the budget) willing to discuss how robust a type of high availability implementation to deploy, or what risks and potential financial losses need to be accepted.
Fine/left
The last important parameter is what happens in case of SLA violation by the service provider. The penalty is usually set according to the time of failure of parts of the service or unavailability of the entire service. In most cases, the fine is quantified as a maximum of one monthly payment for the service.
Since the financial loss in the event of an outage is often many times higher than the penalty paid by the supplier, it is essential to design a truly robust and durable design.
Service architecture in the cloud
Cloud providers allow users of their services to achieve a wide range of availability levels. Most of the time, however, this is not achieved by a magical service configuration slider, but by the right redundant architecture using more of balanced components and location in multiple accessibility zones.
Therefore, when designing a cloud architecture, we will focus on Platform Services (PaaS)that have been discussed in this article. PaaS themselves meet the requirement of robustness, consist of multiple components and have defined SLAs. At the same time, PaaS can be operated in multiple availability zones, are scalable and have handled disaster scenarios, including backups and possible rapid re-deployment of the service.
In case of use infrastructure services of the classic VM type, it is a good idea to consider placing it in a scale-set. This allows you to ensure that additional instances are automatically started on a scheduled basis, while supporting availability zones. Similarly, we need to configure all storage, from the image I'm deploying from to the actual managed disks under each VM through availability zones.
- Microsoft Azure SLA Overview https://azure.microsoft.com/cs-cz/support/legal/sla/summary/
- AWS SLA Overview https://aws.amazon.com/compute/sla/
Highly available application architecture
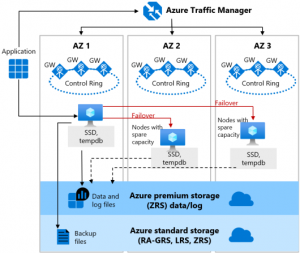
If I want to make applications truly robust and eliminate all possible risks (such as loss of datacenter), I need to architect the design of the components across regions and zones. At the same time, I have to choose automated deployment and redeploy in case of loss or damage. The following figure shows an example of an ASP.NET and SQL Server multi-tier architecture scenario in two SLA variants:
- The first variant has an SLA of 99.95 %: the components are distributed over two regions and the individual resources are within the availabilities of the set. All failover is handled by the Azure trafic manager described in the text below.
- The second variant has an SLA of 99.99 %: it differs from the first variant by dividing it into two more availabilities zones within the two regions. This is maximum possible SLA approaching 100 % with a maximum outage time of 52 min 35 s per year.
The increase in SLA to 99.99 % was achieved by dividing resources into availabilities zones, i.e., two separate physical locations within a region, whereas an availabilities set is a location within a single physical location.
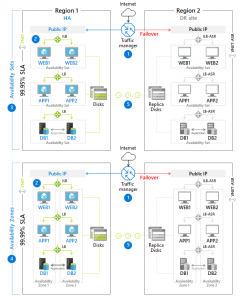
High service availability starts with regions and zones
The basic building blocks of high availability of global service providers are regions and zones. This functionality is similar for both key representatives of global service providers (Amazon Web Services and Microsoft Azure).
Region is completely isolated environmentthat do not share any infrastructure with another region. Individual regions are connected only by backbone connectivity. The regions serve as global fault-domains (geographically separated and isolated datacenters where the failure of one does not affect the other) and aim to completely separate the environment for business continuity & disaster recovery solutions.
It is usually not possible to natively connect two virtual servers from different regions over an internal network, however, it is possible to replicate data. Data connectivity between regions is usually charged for, but is cheaper than internet connectivity.
Zone is meant specific data centre (or several nearby data centres in one location) within the region. Each zone is fully redundant and does not share any infrastructure elements (cooling equipment, diesel generators, network infrastructure, etc.) with another zone.
The zones are interconnected by a high-capacity network with minimal latency and connectivity within the zones is not charged. Virtual servers (or other services) can be located in different zones within the region and are connected by an internal network.
Overview of cloud components worth knowing
Redundancy of virtual instances
Azure VM Scale set or AWS EC2 Auto Scaling are computer auto-scaling services. They allow you to create and deploy hundreds of virtual machines in minutes with built-in load balancing and template-based auto-scaling. By combining VMs and spot instances in one set, great cost optimization can be achieved. When combining a VM scale set and placing it in at least two availability zones, an SLA of 99.99 % can be achieved.

Container redundancy
Azure AKS or Amazon EKS are Enterprise Kubernetes services that cover high availability, scalability, deployment process, management and evaluation scenarios. With support for modern applications that evolve as Microservices architecture and have full support in Kubernetes.
The solution also includes various balancing tools that can scale the number of running instances. I can add any type of VMs from all available series to the AKS/EKS pool and it is possible to use spot instances that are optimal for processing batch jobs. For Build & Deploy, I use the pipeline tools described below.
It's good to know that deploying a Kubernetes cluster in the cloud costs nothing, only the individual running VMs in the pools are charged.
And what happens if your container "dies"? A new (identical) one starts immediately and you don't have to worry about anything. It works the same way when the underlying VM crashes. You just need to decompose the underlying VM and containers properly so that they are still in high 1+n availability during a crash. This model is ideal for both backend and frontend services.
We have discussed this topic in detail in the previous article.
Application Redundancy
Azure App Service is a very interesting alternative to Kubernetes cluster. It also allows you to run many instances of code or container wrapped in Docker. This web application scaling service has an SLA of 99.95 % in the premium tier or in the dedicated isolated tier.
The service includes a load balancer for load distribution and supports private endpoints for connection to the internal network. For publishing content to the Internet, it is usually used in combination with Azure Application Gateway as an L4/L7 application firewall. Like other services, it fully supports CI/CD automatic deployment.
Azure Functions are similar to AWS Lambda and also allow running serverless code in container form. You pay for time and RAM used, and there are a relatively large number of free requests each month.
Azure Loadbalancer or AWS Elastic Load Balancing are platform services that load-balance the distribution of incoming flows that arrive at the front-end services and load-balance the back-end pool instances at layer four (L4) of the model Open Systems Proconnection (OSI).
In addition to the classic load balancers that operate at the L4 layer, cloud providers also provide more advanced application load balancers (in Azure Application gateway) that operate at the seventh layer (L7) of the OSI model to support some additional features such as cookie-based session affinity.
Traditional load balancers at the fourth transport layer operate at the TCP/UDP level and route traffic according to the source IP address and port to the destination IP address and port. In contrast, application load balancers can make decisions based on a specific HTTP request. Another example would be routing based on the incoming URL.
Network redundancy
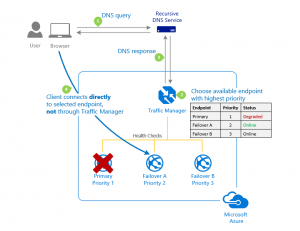
Traffic manager is a DNS-based load balancer that allows you to distribute traffic for applications accessible from the Internet across regions. It also provides high availability and fast response for these public endpoints.
What does it all mean? Simply, it's a way to direct clients to the appropriate endpoints. The traffic manager has several options to do this:
- priority routing
- weight routing
- performance routing
- geographic routing
- multivalue routing
- subnet routing
These methods can be combined to increase the complexity of the resulting scenario to make it as flexible and sophisticated as possible.
At the same time, the health of each region is automatically monitored and traffic is redirected if an outage occurs.
Redundancy RDS
Azure PaaS db services or Amazon RDS (Relational Database Service) offer platform database services including:
- MYSQL
- PostgreSQL
- Maria DB
- Oracle
- SQL server
- Aurora DB (AWS)
- Cosmos DB (Azure)
- SQL Server Managed Instance (Azure).
- and others
For virtually all DB types, you can choose 1+n instances, select the type of HW on which the service will run, use Premium SSDs or Ultra SSDs. As with other services, it is possible to increase resilience by deploying across multiple availability zones, where we can get to SLA 99.99 %. Another advantage of multiple replicas is the ability to use them to optimize read operations.
High availability and cloud storage
In the clouds is many types of storage and we're not going to go into detail about each one. Most of the repositories mentioned below have SLAs starting at 99.9 % up to high availability scenarios with data spread across regions and zones with SLAs reaching 99.999 %.
In Azure, these are Blob Storage, Azure Files, Azure Data Lake, when high performance and low latency are required Azure NetApp Files.
In AWS, these are services Amazon S3, EFS Elastic File System and EBS Elastic Block Store as high-performance and redundant storage.
Even with the highest SLA storage, I have to take into account that I may lose data at some point. Although the probability is minimal (0.001 %, i.e. "once every 10 years at most"), I still have to back up everything.
Content distribution
Azure CDN (Content Delivery Network) or Amazon CloudFront are services for global distribution of content such as web (including images), live stream, video or large files.
The service provides global balancing and caching functionality, having a storage so-called endpoint in virtually every country. This platform service is used in the design of modern web applications to distribute performance, so that repeated downloads of large amounts of static data do not overwhelm web servers.
Components that no highly available modern application can do without
Highly available modern applications still use services like:
Message queuing is a service for queuing and exchanging messages mostly in XML or JSON format. The service is used, for example, to send and receive accounting documents between systems.
In the cloud we have the possibility to use Azure Service Bus, Amazon Simple Queue Service or the developers' favourite RabitMQwhich is also available as PaaS.
Cache as Azure Redis Cache or Amazon ElastiCache are services that help optimize the loading of database content. They significantly speed up the loading and running of web applications and also lighten the load on the database server.
Both services are available as PaaS and can be deployed across regions and availability zones.
Automation of environment deployment (Build & Deploy)
When designing an HA architecture in the cloud, it is necessary to take into account the automation of the deployment environment to reduce deployment time while ensuring the sustainability of code versioning. The ideal is to write everything as IaaC (Infrastructure as a Code) and manage the code in some CI/CD tool like Azure DevOps, Azure Pipelines or CI/CD AWS Pipelines.
This means that I keep the code in a repository (GitHub, Azure DevOps) where I commit and approve changes. Build & Deploy environment I run the pipeline tool first on a test/stage environment to verify functionality, deployment speed and other defined parameters. I then proceed with a live deployment to a production environment. Everything is workflow driven and the whole process is defined and transparently managed. In case of an error, these tools allow to compare different code versions and highlight changes.
For the record, some services such as Azure App Service Plan allow you to deploy a newer version of the code alongside the old one, and then switch between them or flash back. This is a very useful feature when I'm chasing every second of downtime at high SLAs.
This all falls under a discipline called release management.
Chaos engineering testing
After building an architecture that we consider robust enough to meet the target SLA, it is a good idea to find the resources and time to implement testing chaos engineering. We have already written about this in the previous article.
By testing probable failures on individual components, we can determine the real behavior of the application during partial infrastructure and configuration failures. This is the only way to be sure that the architecture matches the real needs.
Why single VM is not enough, even though VM has 99.9 SLA
One final example: why is a single VM not enough? Even with a single VM relatively high SLA 99.9 %, I still have to count on the fact that we will do updates to the operating system, database and application services. Or there will be some data corruption, a disk operating system that doesn't have a fixed SLA, or any other interconnected component.
If a Scale set of at least two VMs is used, the SLA rises to 99.95 % for the last running instance. Placing the Scale set in a minimum of two availability zones brings the SLA to 99.99 % including the assigned disks.
So what do I have to deal with as an architect

There you go:
- networks
- domain records
- firewalls
- routing
- application frontend
- application backend
- scalesets
- database as RDS
- loadbalancery
- CDNku
- message queuing
- application cache
- automatic deployment
- testing
High availability of services in brief
High Availability (HA) is natively supported in the cloud and can be deploy significantly faster than building environments across multiple datacenters in an on-premise environment. I can combine many high availability scenarios and service types in the cloud. Therefore, when designing a service architecture, it is essential to think not only about the high availability of a specific service, but always about the system as a whole, that is, the robustness and resilience of the entire solution.
It is also necessary to take into account disciplines such as patchmanagement of all components, backup and recovery testing, i.e. having a disaster recovery solution whose recovery times also count towards the SLA.
And it all has to be covered business continuity managementwhere I evaluate all possible risks and impacts, on the basis of which the architectural design is adjusted, i.e. the life cycle of the application and the environment.
The primary advantage of cloud solutions is a detailed description of SLAs for all services, logging and monitoring, architectural blueprints and best practice service architecture design that can be used as a basis for design.
Furthermore, it is necessary to address by automating service deploymentdescribing everything as Infrastructure as a Code compared to a solution operated in an on-premise environment, where broken hardware has to be ordered, installed and connected, in the cloud it is enough to "re-deploy".
If you are interested in the issue of high availability, other articles from Cloud Encyclopedia, where you will find some topics related to high availability treated in more detail.



