Monitoring v cloudu

Monitoring dokáže včasnou identifikací problému předejít mnoha malérům, a zachránit tak firmám nemalé ztráty. Nastavit si správně monitorovací strategii však není tak banální, jak se může na první pohled zdát. Obzvláště v cloudu platí, že monitoring není zadarmo, a i proto bychom měli k jeho nasazení přistupovat zodpovědně. Ukažme si, jak na to.
Jakub Procházka
Monitorovací strategie
Společnosti vstupují do cloudu buď s nějakým již existujícím monitorovacím systémem, který je možné integrovat s veřejným cloudem, nebo se vydávají cestou čistě nativních nástrojů od poskytovatelů veřejného cloudu.
Často si to ale lidé představují až příliš jednoduše, kdy se v cloudu zaškrtne nějaké políčko a monitoring je rázem vyřešen. Bohužel tak snadné to není. Monitoring je komplexní služba, o které je třeba uvažovat holisticky (podobně jako v případě zálohování, o němž jsem psal v jednom z předchozích článků).
V první řadě by samotnému monitoringu měla vždy předcházet monitorovací strategie, kterou by si měla společnost zpracovat již před vstupem do veřejného cloudu (nebo alespoň na začátku jeho adopce).
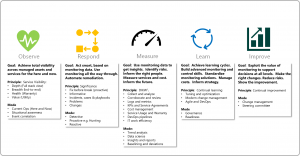
Zdroj: https://docs.microsoft.com/en-us/azure/cloud-adoption-framework/strategy/monitoring-strategy
Z monitorovací strategie by pak mělo vyplývat vše, co bude součástí monitoringu. Kromě definování rozsahu (scope) by společnost neměla zapomenout si ujasnit i následující:
- určit kategorie kritičnosti jednotlivých incidentů (viz následující obrázek),
- zohlednit, kdo bude cílovým příjemcem notifikací,
- brát v úvahu, kdo bude konzumentem logů,
- jaká data budeme chtít vizualizovat.
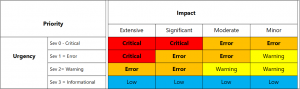
Zdroj: https://docs.microsoft.com/en-us/azure/cloud-adoption-framework/strategy/monitoring-strategy
Monitorovací nástroj by byl sám o sobě k ničemu, pokud by se do logů nikdo nedíval a notifikace by končily ve spamu nebo by se v jejich záplavě příjemce ztrácel.
Současně nám monitorovací strategie vymezí konkrétní rámec monitoringu. Je tak možné se vyhnout zbytečným nákladům spojeným s monitorováním a logováním dat, která ve skutečnosti nemají žádný přínos.
Často se setkávám s tím, že si zákazník plošně zapnul logování na vše a nyní je nemile překvapen stále se zvětšující fakturou. V takových případech je třeba udělat krok zpátky a zrevidovat a zkonsolidovat existující řešení.
Více o monitorovací strategii se můžete dočíst například v oficiálním cloud adoption frameworku od Microsoftu.

Zdroj: https://www.commitstrip.com/en/2019/05/20/monitoring-everything
Monitoring v cloudu – jaké jsou možnosti?
Mezi nejrozšířenější monitorovací služby v cloudu patří Azure Monitor a AWS Cloudwatch. Na tyto služby se mohou následně připojovat další nástroje, včetně nástrojů třetích stran jako například Datadog nebo Splunk.
Obě základní služby umožňují monitoring nejen zdrojů běžících v jejich cloudovém prostředí, ale i mimo něj – nejčastěji na on-premise. Podporují tedy hybridní scénář. Integrace s on-premise a sběr dat se pak provádí pomocí agentů.
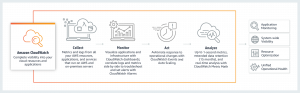
Zdroj: https://aws.amazon.com/cloudwatch
Monitorovaná data
Sbíraná data dělíme do dvou základních skupin, a to na logy a metriky.
Metriky jsou numerické hodnoty, které charakterizují službu v konkrétním čase. Často mohou být zobrazovány v různých grafech a vykreslovány téměř real-time.
Příkladem metriky může být utilizace CPU virtuálního serveru nebo odezva webové aplikace. Některé základní metriky jsou v cloudu sbírány automaticky, pro jiné je třeba doinstalovat agent nebo rozšíření pro danou službu.
Metriky mají nastavenou implicitní retenci, například v Azure je to pro platformní metriky 93 dní. V případě, že chceme metriky uchovávat déle, je nutné „odlévat“ metriky do placeného úložiště.
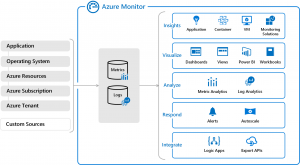
Zdroj: https://docs.microsoft.com/en-us/azure/azure-monitor/overview
Logy jsou standardní strukturované textové záznamy obsahující typicky timestamp, druh informace (warning, error, critical, etc.) a samotný záznam. Pro retenci logů je nutné ukládat je do speciálního úložiště, v případě Azure se jedná o Log Analytics, který považován za jakýsi centrální bod nejen logů, ale celkově monitoringu.
Hlavní oblasti monitoringu v cloudu
Obecně lze monitoring v cloudu dále rozdělit do těchto čtyř kategorií:
- Monitoring platformy poskytovatele
- Aktivity a audit logy
- Monitoring IaaS a PaaS
- Aplikační monitoring
Monitoring platformy
Monitoring platformy poskytuje informace o dostupnosti cloudového prostředí a informuje o nedostupnosti služeb nejen v daném regionu. Zároveň nás předem upozorňuje na plánované práce či odstávky. V kontextu Microsoftu se tato služba nazývá Azure Health a u Amazonu zase AWS Health.
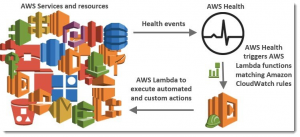
Zdroj: https://aws.amazon.com/blogs/aws/announcing-the-aws-health-tools-repository
Aktivity a auditní logy
Dále bychom měli logovat i aktivity prováděné v cloudu a s tím související další auditní logy, které popisoval kolega Martin Gavanda v předchozím článku. Kromě již zmiňovaných Azure Monitor a AWS Cloudwatch se zde využívají další služby jako Azure Activity log či AWS X-Ray.
Monitoring IaaS a PaaS
Tento typ monitoringu obvykle zajímá uživatele nejvíce, protože na rozdíl od platformy zde vstupuje do hry i odpovědnost klienta, a to dle sdíleného modelu odpovědnosti (který jsme popsali v dřívějším článku).
Monitoring zde hraje významnou roli právě proto, že upozorňuje na případné nedostatky, chyby nebo incidenty ve spravovaném prostředí. Příkladem může být výpadek některého ze serverů (IaaS VM), jeho nevhodná utilizace nebo nedostupnost či přetížení PaaSové databáze.
U PaaS služeb se nabízené možnosti monitoringu mohou lišit dle konkrétního typu služby. V souvislosti IaaS a PaaS monitoringem je třeba zmínit Azure nástroj zvaný Diagnostic settings, který obsahuje aktivity logy, resource logy a poskytuje detailní diagnostiku a auditní informace týkající se Azure zdrojů.
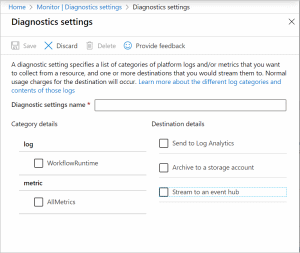
Zdroj: https://docs.microsoft.com/en-us/azure/azure-monitor/essentials/diagnostic-settings
Aplikační monitoring
Když půjdeme ještě o úroveň hlouběji, dostáváme se do vrstvy OS a aplikací. Díky rozšířením a agentům získáme možnost vidět mnohem více detailů, jako například aplikační logy, custom logy aplikace, detaily logů operačního systému a dalších služeb běžících třeba na našem VM/EC2.
U aplikačního monitoringu rovněž platí, že je možné monitorovat i služby běžící mimo dané prostředí, například on-premise.
Pro aplikační monitoring AWS nabízí Amazon CloudWatch Application Insights a Microsoft zase Azure Application Insights. Integrace těchto nástrojů bývá většinou snadná, v některých případech je u vybraných programovacích jazyků podporován i codeless aplikační monitoring (více se o něm můžete dočíst například v oficiální Microsoft dokumentaci zde).
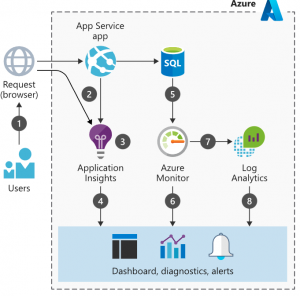
Aplikační monitoring velmi pomáhá vývojovému i DevOps týmu a může výrazně pomoci vylepšit uživatelskou přívětivost aplikace. Je možné sledovat detaily jednotlivých sessions, uživatelů, jejich pohyb v aplikaci, včetně chyb, sledování návratnosti a spoustu dalšího.
Jak uchopit náklady a nasazení monitoringu?
Monitoring může představovat významnou položku na konečné faktuře. Abychom tento dopad minimalizovali, nesmíme kromě monitorovací strategie zapomenout na několik dalších užitečných tipů:
- Používat data sampling
- Omezit množství dat pomocí data cap, resp. daily volume cap
- Využívat slevy z objemu
- Při debuggingu generujícího velký objem logů zapínat vyšší log level pouze na dobu nutnou pro debugging
Nasazení monitoringu je možné provádět automatizovaně (nebo alespoň částečně) například pomocí příslušných tagů nebo v případě IaaC v deployment skriptu.
Sledovat, zda splňuje monitoring požadavky společnosti, lze i pomoci různých politik, které hlídají dodržování pravidel monitoringu u jednotlivých zdrojů a mohou nás na případné nedostatky upozornit.
Automatizace a notifikace
Na jednotlivé incidenty lze reagovat různě. V případě, že dojde ke spuštění (trigger) alertu, je možné poslat e-mail, SMS, vytočit telefonní číslo, založit ticket, poslat notifikaci do aplikace nebo přímo spustit nějaký automatizační skript, který se sám pokusí o nápravu. Tyto akce lze samozřejmě i kombinovat, a to i ve smyslu příjemců, tedy různých skupin, které chceme notifikovat různými způsoby.
Například při nedostupnosti webového serveru na VM je možné poslat e-mail adminům, založit ticket a pokusit se automaticky restartovat webovou službu na VM (apache/nginx/IIS). Pokud se tím problém vyřeší, lze to zaznamenat do ticketu a poslat e-mail adminům, kteří mohou tento neurgentní problém prozkoumat blíže později v rámci pracovní doby. Pokud problém přetrvává, následuje eskalace ticketu a poslání SMS nebo vytočení hovoru na hotline.
Vizualizace
Administrátorům i vývojářům může velmi usnadnit (a především urychlit) práci okamžité vykreslování sbíraných dat. Nejdůležitější data můžeme vizualizovat na tzv. dashboardech, což jsou v podstatě nástěnky, které poskytují rychlý přehled o sledovaném prostředí nebo aplikaci. Často tak získáme důležité informace, co se v našem prostředí děje, již na první pohled.
Vlastní pohledy lze dělat pomocí query dotazů dle aktuální potřeby a je možné je i připnout na vlastní dashboard.
Příklady, jak mohou takové dashboard vypadat v AWS i v Azure, jsou na následujících obrázcích. Schválně – poznáte, který patří ke kterému poskytovateli?
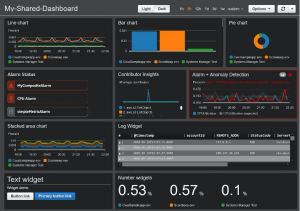
Zdroj: Oficiální stránky poskytovatele
Zdroj: Oficiální stránky poskytovatele
A to není vše…
Existují ještě dva další speciální typy monitoringu, o kterých jsem se dnes nezmínil. Patří totiž do zvláštní kategorie, kterými jsou bezpečnostní monitoring a monitoring nákladů. Každá tato kategorie je samostatným tématem na vlastní článek a je možné, že i k nim se v budoucnu dostaneme.
A jak monitorujte u vás? Šli byste v případě hybrid prostředí raději cestou jednoho nástroje, nebo cloud monitorovali separátně? Dejte mi vědět v komentářích.
Nyní se můžete začít těšit na příští článek, který pro vás připraví kolega Martin Gavanda na téma klíčů. Pokud vás v souvislosti s cloudem zajímají i jiná témata, přečtěte si náš seriál Encyklopedie cloudu – stručný průvodce cloudovým prostředím.



